

Usage-centric Testing part 1: E2E testing, a love/hate relationship

In this two-part article series on Usage-centric Testing, in this first part we are going to explore the importance of relevant E2E testing in software development.
By embracing Agile and DevOps mindsets, software development teams are now able to deliver new value to their customers continuously. The testing process followed the lead and became continuous as well. Teams don’t just test during development, but also before (shift-left) and after, in the context of the application in the production environment (shift-right). This enables companies to deliver high-quality software, at a faster pace.
Testing in production has many advantages. By monitoring an application in its users’ hands, we can quickly discover errors, bugs, and performance issues and fix them before they cause any more damage to our customer’s satisfaction. We can also test two versions of the design of a feature to see which one works better for our users (A/B testing) or even learn how our users appropriate our application.
The knowledge of our user’s behavior can help us design more accurate tests and more targeted test suites, so we can keep improving quality and reducing the release cycle at the same time. In this two-parted blog post, we are going to discuss how this approach we call Usage-centric Testing can help.
Before we dig further into Usage-centric Testing itself, this first part is a reminder about why it is important (and tough) to design and select the most relevant E2E tests possible.
“From the heights of these pyramids…”
Let’s start with our good old pyramid of automated tests:
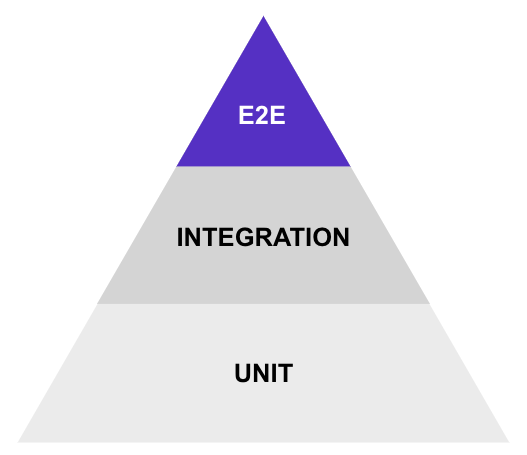
We won’t elaborate on this model, since a lot of authors already wrote about it. See for example this article from Martin Fowler’s website. Let’s focus on the top of the pyramid, aka the E2E tests.
Their position on the pyramid hints at a few facts about those tests:
They are slow to run
Since they need the whole application to start (from the client to the database), they need to get everything up and running before interacting with the system and checking the assertions. This entire build phase itself can be time-consuming (a few minutes). Then, the automation robot will act as a real user would do to follow the test steps (by clicking, typing values in inputs, etc…). Which is way longer than just, for example, changing a value in the database with a SQL command, as an integration test would do (we are comparing seconds to a few milliseconds).
They are expensive to produce and maintain
First, E2E tests need some technical bootstrapping (set dependencies up, database flushing, a set of first automated steps for the basic actions in your application like the login, etc…). Even if writing new test cases becomes smoother with time (once you have a proven library of automated steps), maintenance remains complicated and time-consuming. Every minor change in the UI results in tweaking the E2E test code, involving going back and forth between the code and the test execution to check if our modifications fixed them.
But they give us trust in the integration of all the layers of our application
This is the positive counterpart of the two points above. Yes, they are slow, but they provide the highest confidence that a path won’t break. If a regression occurred at a layer or another (API, UI, database…), the E2E test would detect it if lower-level ones didn’t.
These are the reasons that explain why those tests are at the top of the pyramid. We do want a few of them, only a few, but the good ones. But still, our End-to-End test suites often tend to bloat up and seriously slow down our ability to deliver often and quickly. Here are a few hypotheses explaining why it is so difficult to stick to a minimal amount of those tests.
Cognitive-biased testing
« The number of tests in our test suite grows exponentially… but the number of bugs doesn’t decrease accordingly! »
« We have too many tests and a lot of them cover functionalities that are not relevant anymore… »
« We have limited resources to develop and maintain our E2E tests, we don’t know how to prioritize our test effort… »
This is the kind of statement we can hear when conducting interviews with QA engineers, test managers, and developers we get in touch with during our product discovery work. At some point during the development of a software product, the number of End-to-End tests grows to become a bottleneck that slows down our ability to deliver quickly. Given everything we know about these tests and their position in the test pyramid, how do we eventually get there?
Here are a few possible reasons:
We are risk-averse
As we saw before, the main benefit of End-to-End tests is the confidence they give us in the integration of all the technical layers of our system. Our businesses depend on how reliable our applications are. We just can’t take the risk of delivering an unwell-tested new feature. So, for our peace of mind’s sake, we may be tempted to test more cases than needed at the End-to-End level, when a set of integration/service tests would have been more than enough (with the production and maintenance cost, and shorter feedback advantages that come with them).
We like easiness
End-to-end tests make it possible to do full-integration testing, from the UI to the deeper technical layers of an application. Once your End-to-End test framework is set up, it’s easy to add new cases; by re-using already automated steps, it can almost look like building a LEGO set (except that LEGO sets don’t need maintenance nor suddenly become flaky). This impression of easiness often makes us choose testing at the top of the pyramid level, and neglect the in-between level, aka the integration level (see this article by Mike Cohn, “The forgotten layer of the test automation pyramid”). The risk here is to automate too many test cases at the End-to-End level, where we should do this for the most important ones only.
We test assumptions
When writing acceptance tests, we test how we think our users are going to interact with a new feature. In best cases, the feature has been designed in the most user-centered way possible and has been validated with a few rounds of usability tests and design iterations. But even so, our end-users are… human beings. And as human beings, their behavior is not predictable, and they tend to appropriate our products in ways we weren’t expecting (who would have predicted every smartphone owner would use their expensive high-tech device as a flashlight, seriously?). Point is, it is totally fine to do such things (acceptance tests are not originally designed to avoid regressions), but our assumptions remain as such. We never validate them, so we take the risk of keeping irrelevant E2E tests that we still have to run and maintain.
To conclude with the first part of this article about Usage-centric Testing, we will wonder how do we fix our love/hate relationship with End-to-End tests, so it becomes a “love/love” relationship? As we saw, finding the right minimal set of End-to-End tests is key to balancing test suite execution speed and feature coverage. But how? By focusing our tests on our users’ most important journeys, which are, therefore, the most critical ones to our business. As we can’t do this before delivering new features, we have to “shift right” a bit, so we can incrementally and iteratively improve our test suite by learning from the way our application is used in production.
This is the topic we cover in the second part of this article, Usage-centric Testing part 2: a shift-right approach

Stay tuned!

Smoke Tests: What is-it?
Définition Smoke tests are, according to ISTQB definition: A test suite that covers the main functionality of a component or…
Product Update – March 2024
Hello! 🌸 Spring has arrived with its share of good news: including our Product Update!! The features we’ve been talking…

Combining Usage and Requirement Coverage for Higher Quality
Requirement Coverage in a Nutshell Requirement coverage is a crucial metric in software testing that gauges the thoroughness of the…